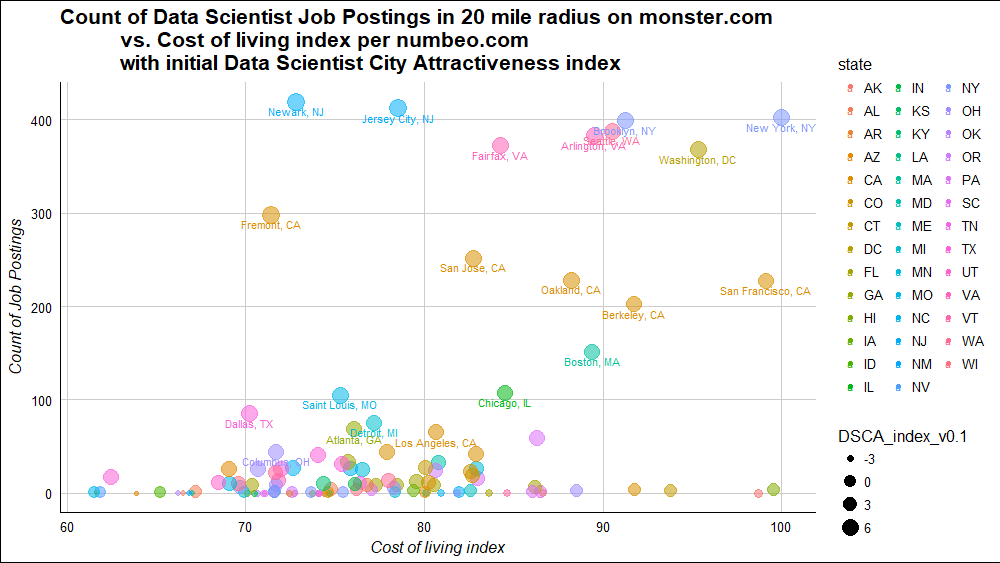
Some cities are more appealing for a data scientist to live than others. Several websites list best cities for data scientists, but their lists don’t agree and their methods are not explained, so the quality of the analysis and ability to determine which individuals their results can be inferred to are limited.
So here I set up to develop a reproducible, if not quite complete, measure of data scientist city attractiveness. Number of jobs for data scientists and cost of living may be two important variables. Using R’s rvest package, we can scrape from the web necessary information to get an idea how cities look in terms of these two. Got to DSCA index v0.1 shown above with top 21 cities labeled.
Bottom Line Up Front: Eight large hiring metros stand out, and less expensive cities within their communing distance look best by these variables. In particular, Newark, NJ, as cheap and close to lots of data scientist jobs, has the highest value in DSCA index v0.1. These two variables alone and the sources I chose show some interesting initial results, but they don’t seem to capture a complete picture, so more work is needed before getting a reliable reproducible index.